БК 1Win была основана в 2016 году под другим названием – FirstBet, но в марте 2018 года была переименована и стала популярной на рынке СНГ именно как 1Win, в том числе благодаря выгодному приветственному бонусу в 500% на первый депозит. Это больше, чем у любых других букмекеров.

АКТУАЛЬНОЕ ЗЕРКАЛО
ВСЕГДА ПОД РУКОЙ
Компания Antillephone NV зарегистрирована на Кипре и имеет официальную лицензию Кюрасао №8048/JAZ2018-040. Наличие лицензии гарантирует надежность, безопасность и прозрачность, в том числе по вопросам выплат.
Ниже мы расскажем, как зарегистрироваться и осуществить 1win вход, если у вас есть аккаунт, и какие бонусы вы можете получить.
| Пункт | Информация о букмекере |
| Время основания | 2016 |
| Штаб-квартира | Кюрасао |
| Телефон службы поддержки | 8 (800) 301-77-89 |
| [email protected] | |
| Продукты | Ставки на спорт, Казино, Покер |
| Маржа (основные лиги, чемпионаты) | 5-10% |
| Live-ставки | есть |
| Статистика | есть |
| Варианты пари | Ординар, экспресс, серия |
| Непопулярные события | Более 10% |
| Виды спорта | Футбол, теннис, волейбол, ММА, крикет, дартс, волейбол, футзал, бейсбол, Формула-1 и еще 20+ |
| Событий по линии | 1000+ |
| Киберспорт | Dota2, StarCraft, League of Legends, CS:GO, Call of Duty |
| Результаты матчей | есть |
| Маржа в прематче (топ-матчи) | До 5% |
| Лицензия | Кюрасао |
| Маржа | 7 - 9% |
| Мобильное приложение | Есть, Android, iOS, ПК |
| Бонус для новичков | 500% на первый депозит |
| Минимальный размер пари | 10 рублей |
| Тотализатор | нет |
| Мобильная версия | есть |
| Видеотрансляции в лайве | есть |
| Средняя маржа | 6-7% |
| Онлайн-чат поддержки | есть |
| Казино 1win | есть |
Плюсы и минусы букмекера
Плюсы:
Бонусная программа: предложения конторы включают щедрые бонусы, в частности, 500% вознаграждение за первое пополнение счета.
Игровые возможности: контора предоставляет широкий ассортимент азартных игр и развлечений, а также обширную линию на множество видов спорта.
Технологичность: качественные мобильные приложения и веб-клиент обеспечивают удобный доступ к ставкам.
Прямые трансляции: на сайте доступны прямые видеотрансляции многих событий.
Регистрация и лояльность: процесс 1win регистрации быстр и прост, а программа лояльности отмечается как хорошая.
Минусы:
Доступность: официальный сайт блокируется на территории Российской Федерации.
Верификация: некоторые пользователи указывают на сложность процесса верификации аккаунта.
Служба поддержки: встречаются отзывы о недружелюбной службе поддержки.
Ограничения ставок: устанавливается потолок ставок для игроков, часто выигрывающих.
Выбор спорта: несмотря на широкую линию, отмечается небольшой выбор видов спорта по сравнению с некоторыми конкурентами.
Коэффициенты: средние кэфы на некоторые события также могут быть восприняты как недостаток.
Чем 1вин отличается от легальных букмекеров в РФ?
| 1win | Легальные букмекеры в РФ |
| Лицензия Кюрасао | Лицензия РФ и налоги в соответствии с российским законодательством |
| Может быть заблокирован в РФ | Прямой доступ для российских пользователей |
| Агрессивная бонусная программа | Более консервативная бонусная политика |
| Платежи через разные системы, включая криптовалюты | Платежи в соответствии с требованиями российского законодательства |
| Широкий выбор ставок и высокие коэффициенты | Ставки и коэффициенты регулируются российским законодательством |
| Азартные игры, такие как казино и покер, кейсы и краш-игры | Ограниченный спектр развлечений: реальные виды спорта и лайв-игры, виртуальный спорт |
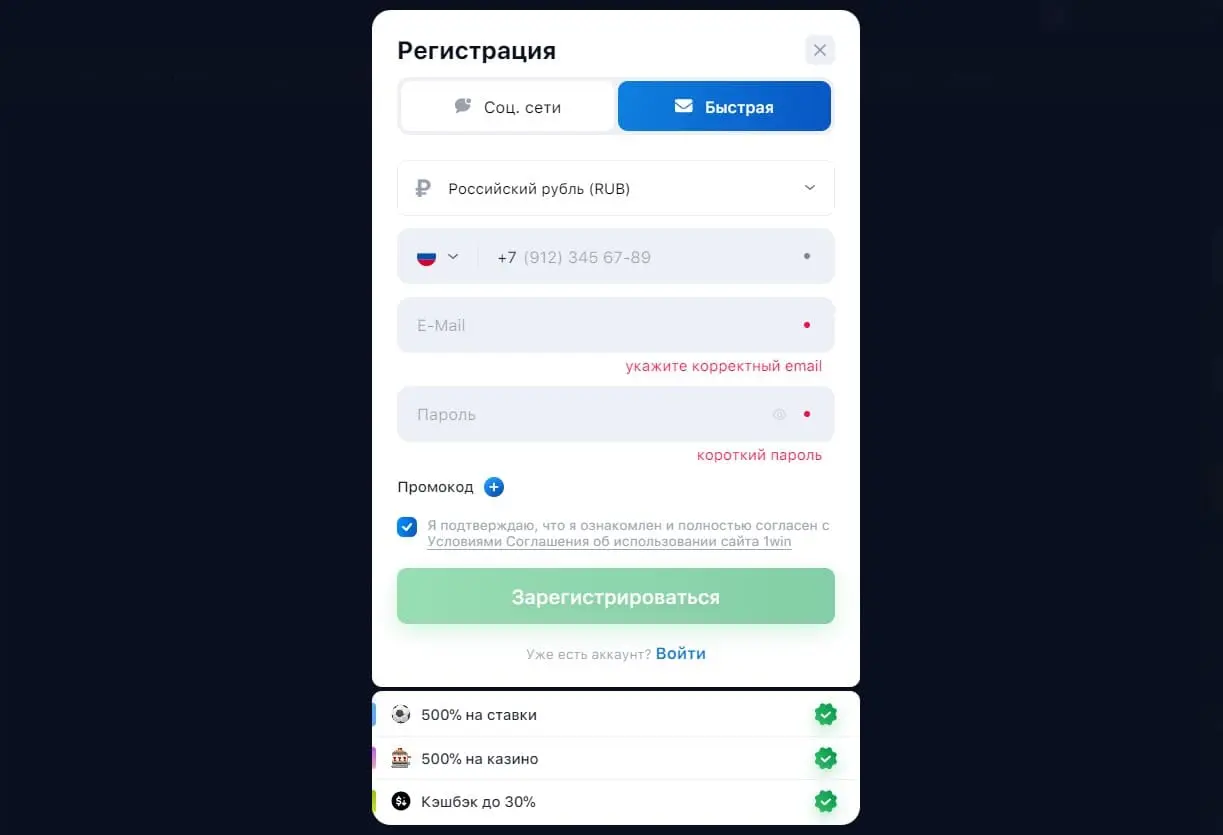
1win регистрация: как открыть личный аккаунт?
Регистрация у БК 1win характеризуется простотой и предлагает несколько способов создания аккаунта:
Через номер телефона и электронную почту: необходимо указать свой номер и e-mail, выбрать валюту счета, которая может быть не только рублем, но и иностранной валютой. 1win Регистрация подтверждается через ссылку, полученную по почте.
Через социальные сети: возможность регистрации с помощью аккаунтов в социальных сетях, таких как ВКонтакте, Одноклассники, Mail, Google, требуется лишь выбор валюты счета.
В 1 клик (если будет возвращен этот метод): выбор страны проживания и валюты счета для быстрой регистрации, предполагающей последующее заполнение личных данных с автоматической генерацией логина и пароля (придут в виде фото или текстового документа).
После регистрации пользователям доступен вход в личный кабинет для внесения денег. В отличие от некоторых платформ, где требуется многоэтапная идентификация, 1win позволяет сразу приступить к ставкам, хотя идентификация может потребоваться в дальнейшем, особенно для вывода средств.
Верификация
Верификация может быть запрошена службой безопасности, особенно при выводе средств. Процесс верификации выглядит следующим образом:
- Авторизация на сайте и переход в профиль.
- Открытие раздела «Идентификация» и ознакомление с требуемыми документами.
- Предоставление фотографий или сканов документов, подтверждающих личность, через форму на сайте.
- В случае использования банковской карты для депозита может потребоваться ее верификация.
Также букмекер может инициировать дополнительную проверку, включая видеоконференцию. Отказ от прохождения верификации может привести к закрытию аккаунта. 1win Регистрация доступна только для лиц старше 18 лет, а использование нескольких аккаунтов и программ для автопари запрещено правилами БК.
Официальный сайт
С момента своего появления в 2016 году сайт неоднократно обновлялся, становясь всё более современным и удобным для пользователя. Поддержка множества языков, включая русский, английский, немецкий, испанский и турецкий, обусловлена международной аудиторией букмекера.
На сайте легко найти следующие разделы, которые предоставляют быстрый доступ к разнообразным функциям:
Главная: здесь выставлены баннеры с акциями и основные события линии.
Live: позволяет делать ставки в режиме реального времени.
Линия: секция предматчевых линий с видами спорта, упорядоченными по популярности.
Игры: разнообразные игровые развлечения.
VSport: открытие игровых кейсов для пользователей.
Кейсы: открытие игровых кейсов для пользователей.
Казино: раздел с казино и слотами.
Live Games: игры с живыми дилерами.
TV Bet: ставки на телевизионные игры и события.
Статистика: аналитическая информация, полезная для беттинга.
1win TV: прямые трансляции спортивных матчей.
Покер: соревнования в покер с реальными игроками.
Дополнительные опции, такие как выбор языка интерфейса, доступ к мобильным приложениям, личный кабинет и вкладка «доступ к сайту», расположены в верхней части экрана. На нижней панели сайта размещена информация о службе поддержки, лицензии, социальные сети и разделы «Правила», «Партнёрская программа», «Мобильная версия», «Бонусы и Акции».
1вин казино
Казино 1win предлагает разнообразный ассортимент азартных игр, включая более 9 000 слотов, созданных как известными мировыми производителями, так и самой компанией. Каждый посетитель сможет найти занятие по вкусу, ведь на платформе доступно множество видов рулетки, покера, блэкджека, а также других настольных и карточных игр. Среди игровых предложений казино также можно найти:
- Слоты: от классических вариантов до современных новинок с ярким оформлением и эффектами, слоты от топовых провайдеров вроде NetEnt , Pragmatic и других.
- Блэкджек: популярное карточное развлечение с простыми правилами.
- Виртуальные игры: позволяют участвовать в играх в виртуальном формате против системы.
- Скретч-карты: виртуальные карты с секретной информацией, где задача игрока — угадать содержимое.
- Лотереи: игры на удачу с случайным выбором выигрышных номеров.
- Live игры: игры с живыми дилерами, транслируемые из специальной студии.
- Aviator: краш игра с генератором случайных чисел, предлагающая умножение ставки.
- Бесплатные игры: демо-версии игр и возможность использования бездепозитных бонусов для тестирования стратегий.
- Турниры: регулярные турнирные состязания с призами для одного или нескольких участников.
Информация о турнирах и акциях размещается на главной странице казино, в социальных сетях, чатах, на каналах мессенджеров и на сторонних ресурсах, посвященных игорной тематике.
Бонусы в 1win казино и БК
Вот таблица с перечнем бонусов, предлагаемых казино 1win, и условиями их получения:
| Вид бонуса | Условия получения |
| Приветственный подарок | Для новых пользователей. Бонус до 500% и 5 000 рублей на первый депозит с ограничением в 50 000 рублей. Отыгрыш через «Ординар» с коэффициентом 3+. |
| Экспресс | Бонус за удачный экспресс из 5%+ матчей. Процент возрастает с количеством событий: от 5 событий - 7%, до 11 и более событий - 15%. Без отыгрыша. |
| Кешбэк | Возврат части суммы, потраченной на слоты. Процент кешбэка 5-25%, зависит от суммы ставок и статуса аккаунта. Без отыгрыша. |
| Ваучеры | Промокоды в официальных группах ВК и ТГ-каналах, раз в 7 дней. Ввод промокода через вкладку "Промо" в личном кабинете. |
| Установка приложения | Скачивание бесплатного приложения для IOS и Android. Бонус 5000 рублей после установки и входа в аккаунт. Отыгрыш с коэф. 1.1+. |
Пари на спорт
Букмекерская контора 1win представляет широкий спектр спортивных дисциплин для ставок, охватывая около 20 видов спорта, включая основные соревнования по футболу, хоккею, теннису и баскетболу, а также киберспортивные игры, такие как Counter-Strike , League of Legends, Dota 2, StarCraft II и Rainbow Six.
Ставки на спорт на зеркало 1win характеризуются глубокой росписью событий, где число предлагаемых рынков для центральных футбольных событий достигает более 120 вариантов, в том числе ставки на статистику, карточки и угловые. Для тенниса в разгар сезона доступно до 50 турниров, включая матчи Большого шлема и другие значимые соревнования. В баскетбольном разделе представлены Национальная баскетбольная ассоциация и крупные европейские чемпионаты.
Коэффициенты в 1 win разнятся в зависимости от популярности и уровня события, с более низкими маржами для топовых матчей и немного выше для менее популярных событий. Для ведущих футбольных матчей комиссия составляет 6-7%, для хоккейных событий уровня финала плей-офф Кубка Стэнли — около 4,5-6%, а для теннисных топ-событий маржа варьируется в пределах 5-7%. В целом, маржа в прематче колеблется в районе 6-7%, что обеспечивает среднюю величину коэффициентов по рынку.
В меню прематча также представлен специальный раздел «Эксклюзивная линия», предлагающий пари на нестандартные исходы, такие как трансферы и увольнения тренеров. Уровень котировок на 1 win часто оценивается ниже 1,90 для равновероятных исходов.
Live-сервис
Букмекерская контора 1win предоставляет обширные возможности для ставок в режиме реального времени, ежедневно открывая доступ к 700-800 событиям лайв, число которых может удваиваться в выходные дни. В лайв-секции доступны почти все виды спорта, представленные на платформе.
Роспись лайв ставок варьируется в зависимости от популярности и важности события: для менее популярных футбольных матчей предлагается около 15 вариантов ставок, тогда как для значимых футбольных событий число маркетов может достигать 60-80. Для хоккейных матчей доступно 40-50 рынков, для тенниса — 15-25, а для баскетбольных игр — 70-90.
Коэффициенты в режиме лайв для топовых событий имеют среднюю маржу в пределах 7-9%, но для второстепенных лиг и чемпионатов маржа может возрастать до 12% и выше. Расчет ставок производится быстро, в течение 15-20 минут после получения официальной информации.
Несмотря на некоторые недочеты, такие как отсутствие графических трансляций и суженная роспись, букмекер предлагает удобную навигацию по лайв-разделу и доступ к видеотрансляциям различных видов спорта, включая футбол, киберспорт и хоккей.
Методы пополнения счета и вывода на зеркале 1win
Для пополнения счета в букмекерской конторе доступны следующие методы:
| Метод | Минимальный депозит | Время зачисления/вывода |
| Банковские карты Visa, MasterCard, Maestro | 500 рублей для карт, различается для других систем | Мгновенное зачисление, вывод: 1-60 минут или до 24 часов в зависимости от системы |
| Криптовалюты (Bitcoin, Tether, Ethereum) | 3000 рублей для Bitcoin, 1750 рублей для Ethereum, 1500 рублей для Tether | Мгновенное зачисление, время вывода не указано |
| Платежные системы (Skrill, Qiwi, ЮMoney, WebMoney, MuchBetter) | 150 рублей для ЮMoney, различается для других систем | Мгновенное зачисление, вывод: до 48 часов для электронных кошельков |
| Касса24, ATF24, UzCard, Piastrix | 100 рублей для Piastrix, 950 рублей для Касса24 и ATF24, 50 рублей для UzCard | Мгновенное зачисление, вывод: 1 рубль для Homebank, время для других систем не указано |
Для вывода средств предусмотрены такие варианты:
| Метод | Минимальный депозит | Минимальный депозит | Время зачисления/вывода |
| Банковские карты Visa, MasterCard, Maestro | 1500 рублей для карт | 75 000 рублей для карт | Мгновенное зачисление, вывод: 1-60 минут или до 24 часов в зависимости от системы |
| Криптовалюты (Bitcoin, Tether, Ethereum) | 4000 рублей для Tether | от 1000 | Мгновенное зачисление, время вывода не указано |
| Платежные системы (Skrill, Qiwi, ЮMoney, WebMoney, MuchBetter) | 150 рублей для Yandex.Money, 10 рублей для остальных платежных систем | 10 000 рублей для Qiwi-кошелька, 15 000 рублей для Yandex.Money | Мгновенное зачисление, вывод: до 48 часов для электронных кошельков |
| Касса24, ATF24, UzCard, Piastrix | 350 рублей для UzCard, 100 рублей для Payeer | 191 967 рублей для AdvCash | Мгновенное зачисление, вывод: 1 рубль для Homebank, время для других систем не указано |
Время обработки запросов на вывод средств может варьироваться в зависимости от выбранного способа, но в большинстве случаев занимает не более одного часа.